Pertumbuhan pesat volume dan kompleksitas data geospasial, terutama dari citra satelit dan penginderaan jauh, menimbulkan tantangan komputasi yang signifikan. Dataset berukuran masif sering melampaui kemampuan perangkat lunak GIS tradisional seperti QGIS atau ArcGIS Pro, sehingga diperlukan pendekatan pemrosesan yang lebih efektif dan efisien. Metode konvensional sering mengalami inefisiensi, penggunaan memori tinggi, dan waktu pemrosesan yang lama. Selain itu, banyak data geospasial bersifat dinamis dan memerlukan pembaruan berkala, seperti data perkotaan atau pemantauan bencana alam. Hal ini membutuhkan metode pemrosesan yang tepat dan andal untuk menjamin akurasi dan kualitas data. Pendekatan standar yang membaca seluruh file ke dalam memori menjadi tidak praktis untuk data raster berukuran besar, menyebabkan operasi I/O disk dan overhead komputasi yang tidak perlu. Oleh karena itu, teknik pemrosesan data yang efisien dan terukur sangat penting untuk mengatasi tantangan ini.
Partisi Rekursif dan Metode Quadtree
Untuk mengatasi masalah pemrosesan dataset geospasial berukuran besar, saya meneliti metode penanganan data lanjutan yang dapat diimplementasikan menggunakan Python. Temuan utama adalah penggunaan metode rekursif untuk memproses data dalam bagian-bagian yang lebih kecil dan mudah dikelola. Pendekatan ini efektif karena membagi dataset besar menjadi bagian-bagian kecil, mengurangi jumlah data yang perlu disimpan di memori dan meminimalkan pembacaan data yang tidak perlu.
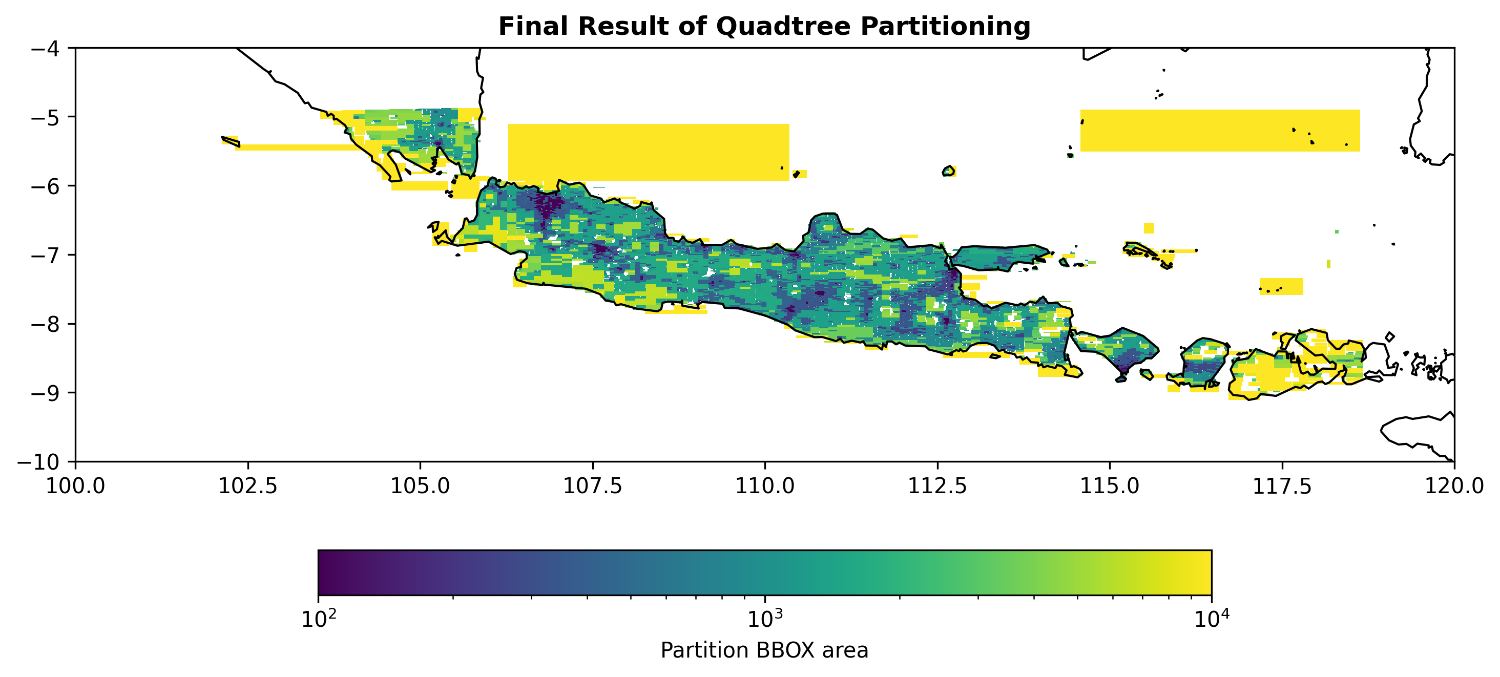
Metode spesifik yang saya adopsi adalah quadtree. Quadtree adalah struktur data pohon di mana setiap node internal memiliki empat anak. Metode ini mempartisi ruang dua dimensi dengan membaginya secara rekursif menjadi empat kuadran atau wilayah. Quadtree sangat cocok untuk data geospasial karena dapat menangani hierarki spasial dan variasi kepadatan data secara efisien. Dengan menerapkan quadtree, file raster besar dapat dipecah menjadi ubin-ubin kecil yang mudah dikelola dan dapat diproses secara independen.
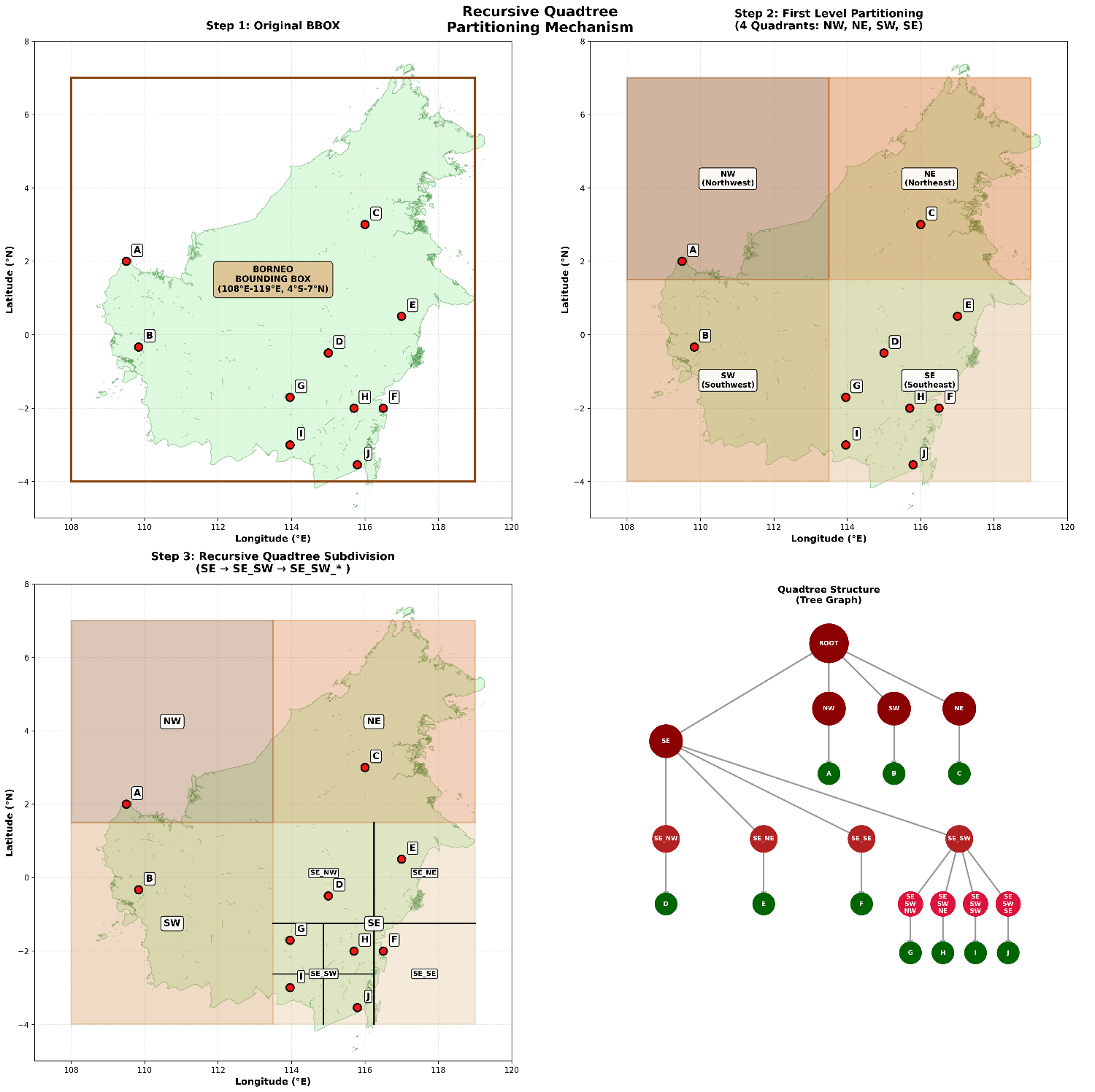
Gambar 1. Pemrosesan data spasial secara rekursif menggunakan Quadtree
Studi Kasus: Data Terdistribusi Merata dan Tidak Merata
Untuk memvalidasi efektivitas metode pembagian rekursif menggunakan quadtree, saya mengembangkan beberapa studi kasus. Kasus pertama menggunakan dataset raster, yang mewakili data geospasial terdistribusi merata dengan titik data atau fitur tersebar seragam di seluruh area. Dalam skenario ini, quadtree mempartisi ruang menjadi bagian-bagian berukuran sama, memungkinkan pemrosesan paralel setiap kuadran. Pembagian didasarkan pada derajat maksimum 5. Metode rekursif memastikan proses ini diulang hingga setiap bagian memiliki ukuran yang sesuai untuk analisis efisien.
Studi kasus kedua menggunakan dataset Open Buildings V3 Polygons, sebuah skenario lebih realistis di mana data terkonsentrasi di area tertentu (seperti pusat kota) dan jarang di area lain (seperti daerah pedesaan). Sifat adaptif dari quadtree sangat penting di sini. Algoritma pembagian rekursif secara efisien mendeteksi kepadatan data dan membuat kuadran lebih kecil dan detail di area berkepadatan tinggi, sementara membuat kuadran lebih besar di area berkepadatan rendah. Pembagian ditentukan berdasarkan batas maksimum 10.000 fitur bangunan per bagian. Pendekatan ini secara signifikan mengurangi pembacaan data yang tidak perlu dan mengoptimalkan pemrosesan dengan memfokuskan sumber daya komputasi pada area yang paling membutuhkan.
Analisis
Kasus 1: Partisi Data Spasial Rekursif dengan Pendekatan Derajat Bujur-Lintang Maksimum
Untuk menguji efektivitas metode partisi rekursif, studi kasus pertama berfokus pada pemrosesan data raster berukuran besar. Pendekatan ini bertujuan meminimalkan pembacaan data yang tidak perlu dengan memecah dataset menjadi segmen-segmen yang lebih kecil, sehingga meningkatkan efisiensi komputasi.
Pendekatan dan Data
Dalam kasus ini, partisi dilakukan pada data geospasial yang mencakup wilayah Indonesia. Dua dataset utama digunakan:
-
1.Batas Administrasi Wilayah: Data poligon batas administrasi level 2 Indonesia dari GADM yang berfungsi sebagai referensi spasial untuk menentukan area yang relevan. Ukuran total: 4.8MB.
-
2.Dataset Tutupan Pohon (Tree Cover): Dataset raster beresolusi tinggi dari Hansen Global Forest Change (Hansen Tree Cover) yang mewakili data raster terdistribusi merata. Ukuran dataset yang sangat besar ini menjadikannya tantangan ideal untuk metode partisi rekursif. Ukuran total: 2.12GB.
Langkah 1: Kalkulasi Indeks Bounding Box dengan Quadtree
Langkah awal proses ini adalah menciptakan indeks spasial untuk seluruh wilayah studi. Metode quadtree digunakan untuk mempartisi boundinbounding boxsia secara rekursif. Proses ini membagi setiap kotak spasial (kuadran) menjadi empat sub-kuadran yang lebih kecil. Rekursi berlanjut hingga setiap kuadran mencapai ukuran tidak lebih dari 5 derajat bujur-lintang pada kedua dimensinya. Ambang batas ini memastikan setiap segmen yang dihasilkan cukup kecil untuk diproses secara efisien tanpa membebani memori sistem.
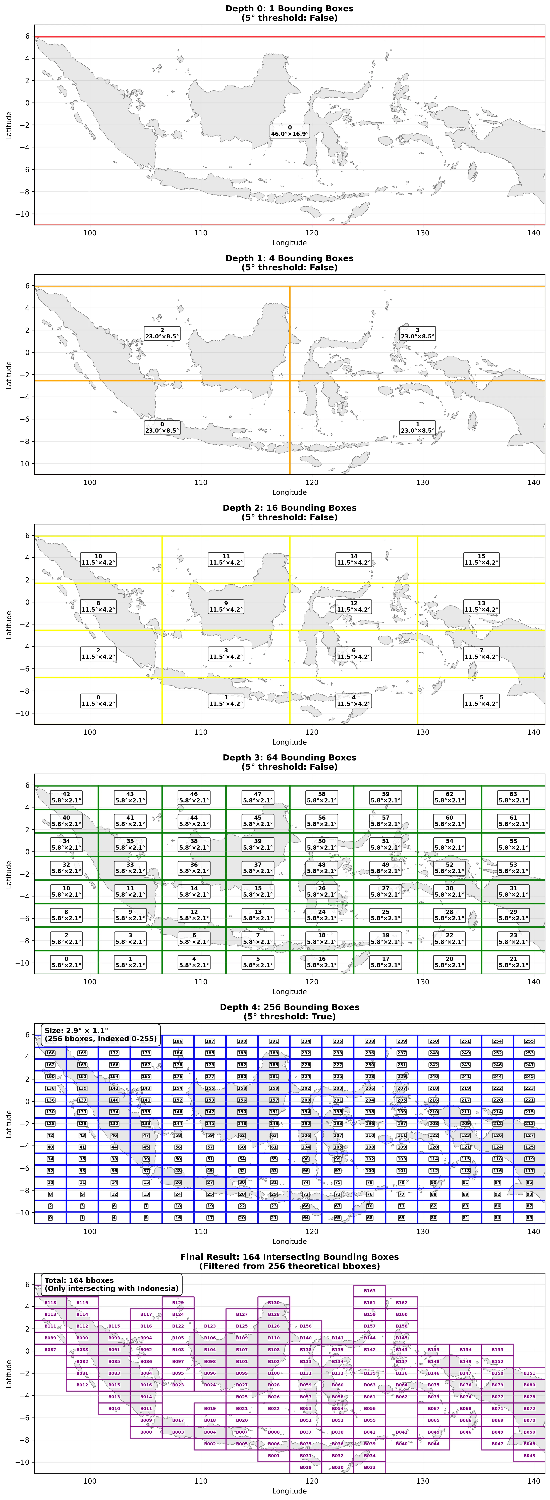
Gambar 2. Proses dalam menghasilkan bounding box secara rekursif menggunakan Quadtree dengan parameter nilai maksimum bujur-lintang
Dengan pendekatan ini, bounding box awal yang mencakup seluruh wilayah Indonesia dipecah menjadi banyak bounding box yang lebih kecil. Hasilnya, 164 bounding box164 bounding box validat dengan indeks unik dari B000 hingga B163. Setiap bounding box memiliki ukuran seragam sekitar 3,05 derajat persegi, memenuhi batasan maksimumaksimum 5 derajatitetapkan. Metode ini menggunakan subdivisi quadtree rekursif yang sistematis, hanya menyimpan bounding box yang beririsan dengan wilayah Indonesia, dan menghindari duplikasi. Hasilnya adalah potongan data berukuran optimal yang siap untuk pemrosesan raster yang efisien.
Proses rekursif ini dapat divisualisasikan dalam beberapa tahap kedalaman. Pada Kedalaman 0, bounding box awal Indonesia bounding box.04° × 16.94°. Pada Kedalaman 1, area ini terbagi menjadi 4 kuadran berukuran 23.02° × 8.47°. Rekursi berlanjut ke Kedalaman 2 dengan 16 kuadran (masing-masing 11.51° × 4.24°) dan Kedalaman 3 dengan 64 kuadran (masing-masing 5.75° × 2.12°). Pembagian berhenti pada Kedalaman 4, ketika kuadran mencapai ukuran 2.88° × 1.06°—di bawah ambang batas 5 derajat. Setelah menyaring area yang tidak beririsan dengan batas administrasi Indonesia, diperoleh 164 bounding box valid.
Langkah 2: Memecah Data Raster Berdasarkan Bounding Box
Langkah kedua menggunakan bounding box dari proses quadtree untuk memecah dataset raster besar. Alur kerja ini memastikan ekstraksi data yang efisien dan akurat.
Prosesnya dimulai dengan memuat 164 bounding box valid, kemudian mengidentifikasi semua file raster Hansen Global Forest Change yang beririsan dengan setiap bounding box. Untuk menghindari ketidakcocokan dimensi dan menjamin data yang mulus, diterapkan pendekatan "gabung dulu, lalu potong".
Semua raster yang beririsan dengan bounding box tertentu digabungkan menggunakan fungsi rasterio.mergebungan kemudian dipotong sesuai dimensi bounding box yang tepat. Proses ini diulang untuk seluruh 164 bounding box, dengan setiap hasil pemotongan disimpan sebagai file TIF tunggal yang dinamai berdasarkan indeks uniknya (misalnya, B001.tif, B002.tif).
Metode ini berhasil menghasilkan 130 file raster terpadu dengan penggabungan yang tepat dan cakupan lengkap untuk setiap bounding box. Deteksi irisan yang efisien dan pengelolaan file sementara menghasilkan jalur persiapan data yang sangat efisien dan otomatis.
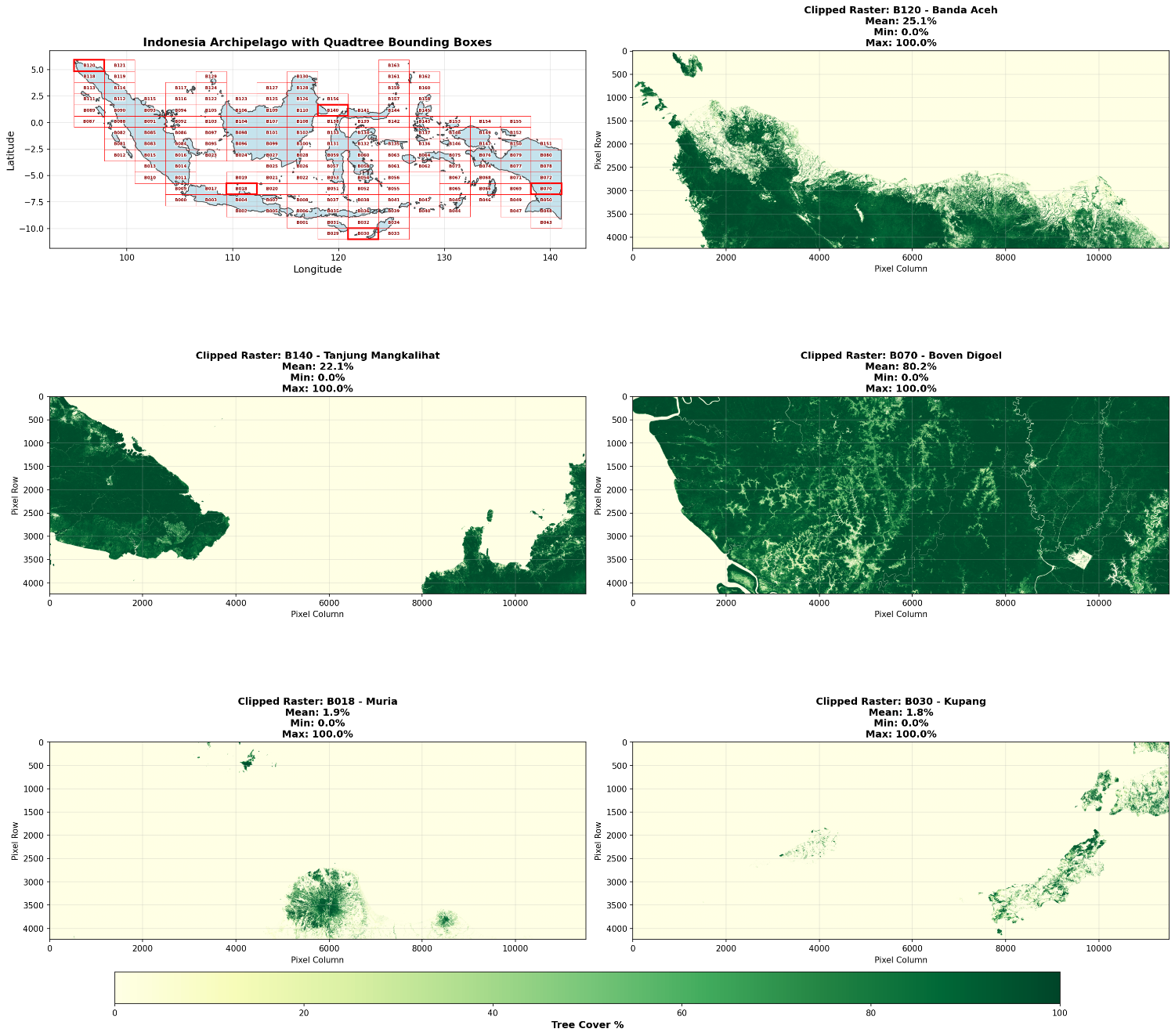
Gambar 3. Hasil clip data raster berdasarkan bounding box yang sudah dilakukan pemisahan secara rekursif
Langkah 3: Klasifikasi Tutupan Pohon berdasarkan Wilayah Administrasi
Implementasi dari proses partisi yang telah dilakukan adalah mengklasifikasikan data tutupan pohon dan menghasilkan analisis pada tingkat administratif. Pemrosesan ini memuat file raster yang telah dipotong dan batas administratif dari GADM. Kemudian menetapkan kategori klasifikasi tutupan pohon: Sangat Jarang (< 10%), Jarang (10-30%), Sedang (30-50%), Padat (50-75%), dan Sangat Padat (> 75%).
Untuk 502 wilayah administratif level 2, proses ini mengidentifikasi file raster yang beririsan dengan wilayah tersebut, memotong data sesuai batas administratif, dan mengklasifikasikan setiap piksel ke kategori yang sesuai. Pendekatan ini menghasilkan penghitungan persentase yang akurat dari setiap kategori tutupan pohon di tiap wilayah, menghasilkan output komprehensif dalam file CSV dengan statistik terperinci untuk setiap distrik dan provinsi. Proses ini memanfaatkan partisi quadtree untuk akses data yang efisien, memastikan analisis menyeluruh di seluruh wilayah administratif Indonesia.
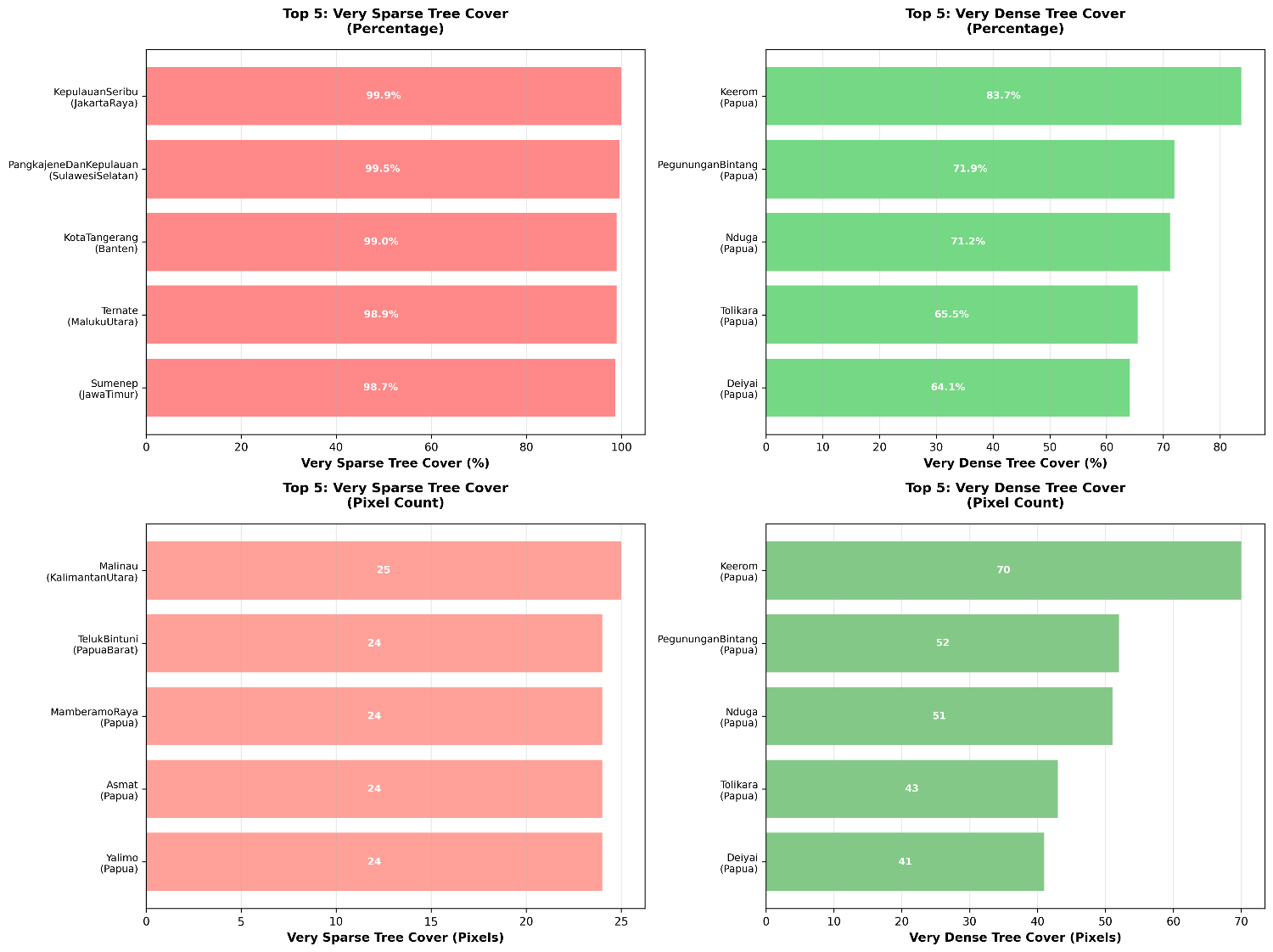
Gambar 4. Pemrosesan data tutupan pohon menggunakan Admin 2 dari GADM dataset
Langkah 4: Analisis Efisiensi untuk Jakarta Pusat
Untuk menunjukkan peningkatan efisiensi dari metode partisi rekursif, saya membandingkan secara langsung proses analisis wilayah Jakarta Pusat. Perbandingan ini menyoroti pengurangan volume data dan waktu pemrosesan yang signifikan dengan pendekatan quadtree yang tepat sasaran, dibandingkan dengan cara konvensional yang memuat seluruh file raster.
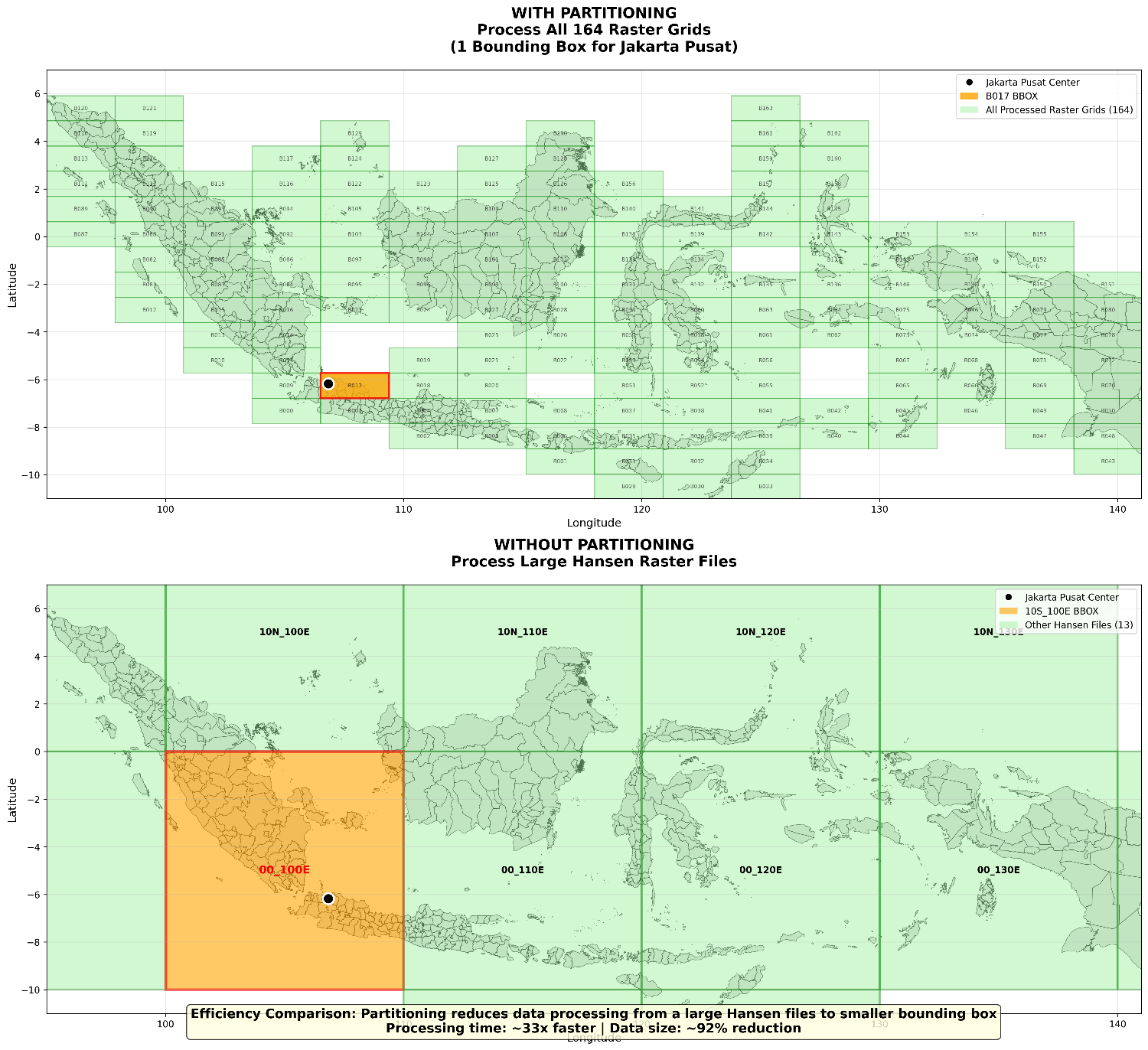
Gambar 5. Perbandingan pemrosesan data raster Hansen dengan dan tidak menggunakan partisi Quadtree
Dengan Partisi (Tepat Sasaran): Proses hanya memerlukan satu file boundinbounding box yang mencakup Jakarta Pusat. BoundinBounding boxrukuran sekitar 3.05° × 1.06° dengan total 48.8 juta piksel. Pendekatan ini memungkinkan akses data yang cepat, karena hanya memproses bagian data yang relevan.
Tanpa Partisi (Cakupan Penuh): Pendekatan tradisional mengharuskan pemrosesan keseluruhan file raster Hansen (00N_110E) yang mencakup Jakarta Pusat. File ini berukuran sekitar 10° × 10° dengan total 1.6 miliar piksel. Pemrosesan dataset sebesar ini jauh lebih lambat dan tidak efisien, karena sebagian besar data tidak relevan untuk analisis.
Hasil menunjukkan peningkatan efisiensi luar biasa: pendekatan partisi 33 kali lebih cepat karena hanya memproses sebagian kecil data. Ini mewakili pengurangan volume data sekitar 92%, membuktikan efektivitas partisi spasial rekursif untuk analisis geospasial skala besar.
Kasus 2: Partisi Data Spasial Rekursif dengan Pendekatan Jumlah Poligon Maksimum
Untuk menunjukkan fleksibilitas metode partisi rekursif di luar data raster, studi kasus kedua menggunakan data poligon dari dataset Google Open Buildings. Tujuannya adalah memproses sejumlah besar fitur secara efisien dengan memastikan setiap segmen yang dipartisi berisi jumlah bangunan yang dapat dikelola, sehingga mencegah kelebihan beban memori dan mempercepat analisis tingkat fitur.
Pendekatan dan Data
Dalam kasus ini, partisi dilakukan pada data geospasial yang mencakup batas administratif Jawa dan Bali. Dua dataset utama digunakan:
-
1.Batas Administrasi Wilayah: Data batas administrasi level 1 dan 2 dari GADM untuk provinsi-provinsi di Jawa dan Bali sebagai referensi spasial. Ukuran total: 1MB.
-
2.Dataset Poligon Bangunan: Dataset Google Open Buildings dalam format CSV. Untuk menangani ukurannya yang sangat besar, analisis ini berfokus pada ubin quadkey tertentu: , , dan . Ukuran total: 22.06GB.
Langkah 1: Konversi Data CSV ke GeoPackage
Langkah awal dalam alur kerja ini adalah mengonversi data tabular besar dari file CSV Google Open Buildings ke format geospasial yang tepat. Untuk menangani skala yang sangat besar ini, sebuah kluster komputasi terdistribusi Dask disiapkan untuk memungkinkan pemrosesan paralel. Pendekatan yang dioptimalkan ini memproses ketiga file CSV mentah—2dd_buildingngildingsi lebih dari 85,8 juta baris data. Alur kerja mengonversi data poligon WKT untuk setiap bangunan menjadi geometri shaambil mempertahandan confidatribut asli seperti lintang, bujur, dan confidence. Akhirnya, data yang telah diproses disimpan sebagai file GeoPackage (.gpkg) terpisah menghasilgpgpkg, gpkg.
Langkah 2: Pemrosesan dan Partisi Geometri
Langkah ini menerapkan strategi partisi untuk mengelola dan memproses jutaan fitur bangunan secara efisien. Dengan menggunakan metode quadtree, data dipartisi menjadi 20.433 segmen yang dapat dikelola, masing-masing berisi antara 46 hingga 8.325 fitur. Hasil akhir disimpan dalam file Parquet yang terstruktur dalam hierarki direktori, memfasilitasi akses data dan skalabilitas di masa depan. Pendekatan ini memastikan distribusi data yang optimal, menciptakan solusi penyimpanan yang efisien untuk analisis geospasial berskala besar.
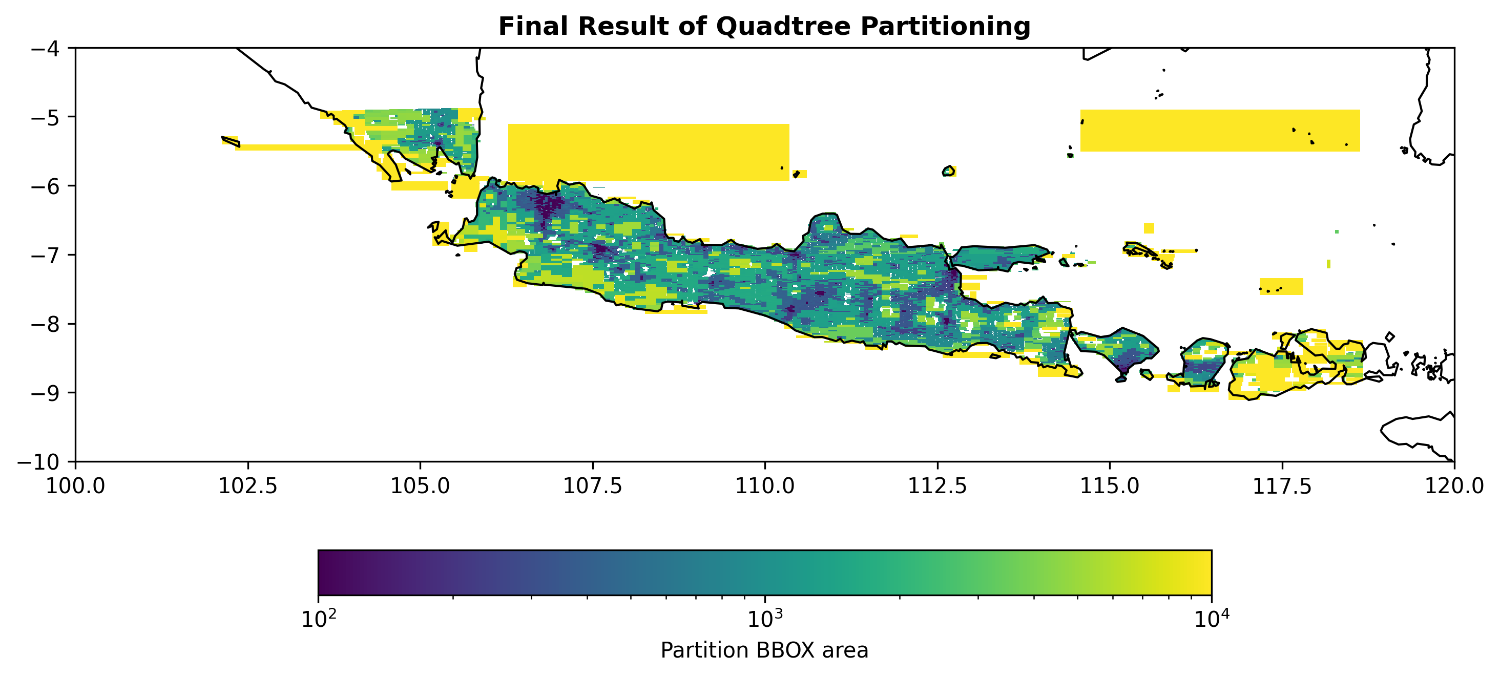
Gambar 6. Hasil akhir pemrosesan rekursi Quadtree pada dataset Google Open Building di sekitar Pulau Jawa-Bali
Berikut adalah distribusi partisi pada setiap level kedalaman pohon quadtree:
- Kedalaman 1: 0 partisi
- Kedalaman 2: 2 partisi
- Kedalaman 3: 9 partisi
- Kedalaman 4: 25 partisi
- Kedalaman 5: 105 partisi
- Kedalaman 6: 445 partisi
- Kedalaman 7: 2.448 partisi
- Kedalaman 8: 7.093 partisi
- Kedalaman 9: 7.327 partisi
- Kedalaman 10: 2.979 partisi
Proses partisi spasial Google OpenBuildings Dataset untuk wilayah Jawa-Bali menggunakan metode Quadtree yang membagi area geografis menjadi empat kuadran yang lebih kecil secara berulang seperti yang terlihat pada gambar. Partisi ini efisien mengelola data bangunan dalam jumlah besar dengan aturan bahwa setiap partisi akhir ('leaf node') tidak boleh berisi lebih dari 10.000 fitur bangunan. Ketika suatu kuadran melebihi batas ini, sistem akan membaginya lagi hingga setiap kuadran baru memenuhi kriteria, sehingga mencegah area dengan kepadatan data yang terlalu tinggi.
Sistem ini menggunakan penomoran spesifik untuk setiap kuadran: 1 untuk Barat Daya (Bd), 2 untuk Tenggara (Tg), 3 untuk Barat Laut (Bl), dan 4 untuk Timur Laut (Tl). Dengan penomoran ini, jalur seperti 1/3/2 secara unik mengidentifikasi lokasi spesifik yang menunjukkan urutan pembagian: dari titik awal ke kuadran Barat Daya, kemudian ke sub-kuadran Barat Laut, dan akhirnya ke sub-kuadran Tenggara. Pendekatan sistematis ini menghasilkan struktur hierarki optimal untuk penyimpanan dan pencarian data, sehingga mempercepat dan meningkatkan efisiensi pencarian lokasi bangunan di daerah padat.
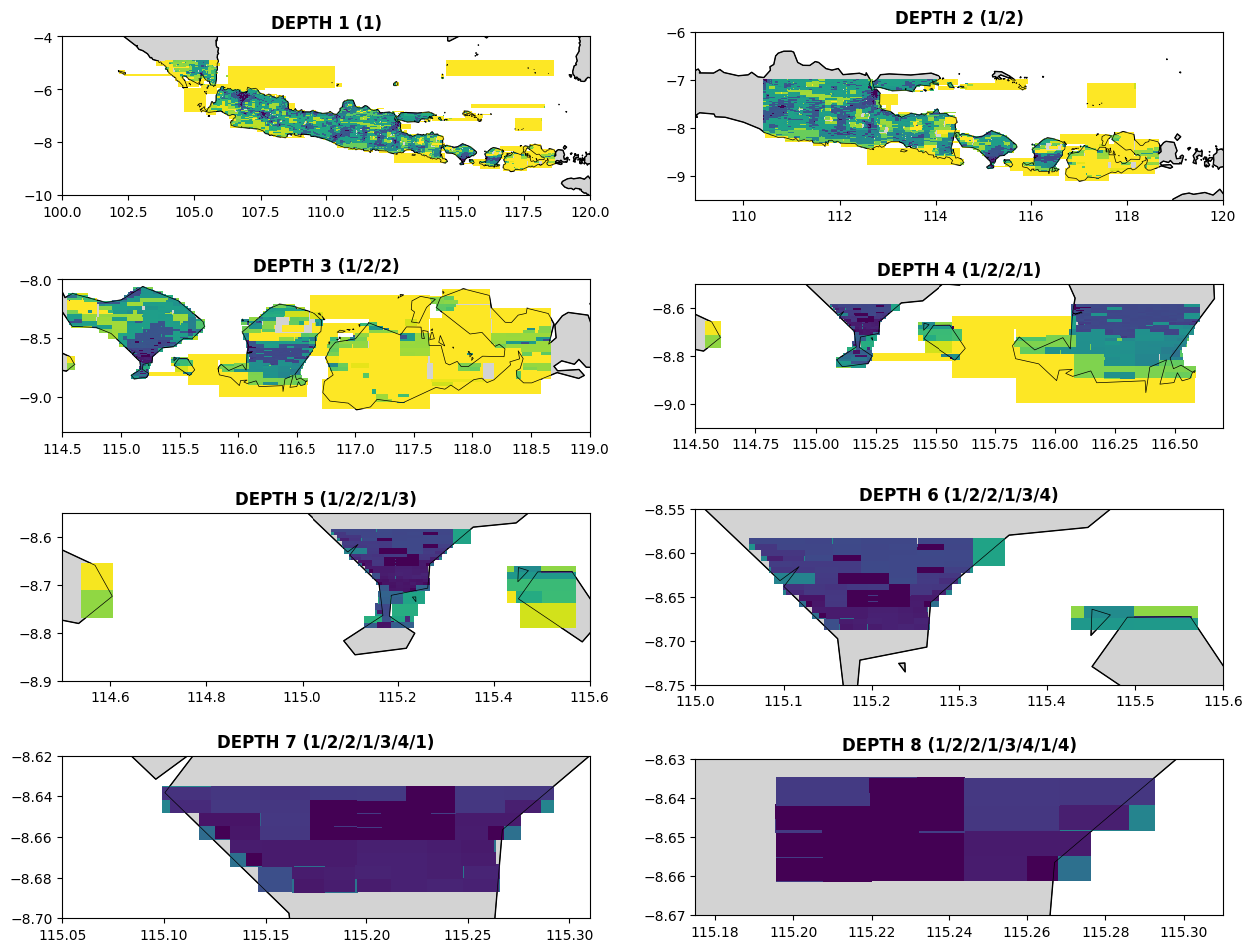
Gambar 7. Simulasi kedalaman partisi Quadtree sekitar pulau Jawa-Bali
Langkah 3: Memproses Data Bangunan di sekitar Jakarta Pusat
Dalam analisis data geospasial, pengolahan data Google Open Building di Jakarta Pusat menjadi studi kasus penting yang menunjukkan efektivitas metode Quadtree partitioning. Tanpa metode partisi ini, pendekatan standar mengharuskan pemuatan seluruh dataset grid "2e7" berukuran 5.9GB yang mencakup lebih dari 60 juta bangunan (60.037.155 entitas). Beban data sebesar ini secara langsung menurunkan performa komputasi, menyebabkan latensi tinggi dan penggunaan memori yang boros.
Dengan menerapkan Quadtree partitioning, proses menjadi jauh lebih optimal. Metode ini membagi ruang geografis secara hierarkis, sehingga memungkinkan identifikasi partisi data yang relevan secara spesifik. Untuk Jakarta Pusat, pendekatan ini berhasil mengisolasi data ke dalam 73 partisi unik. Dibandingkan dengan dataset utuh berukuran 5.9GB, partisi-partisi ini memiliki total ukuran file gabungan hanya 80.6MB.
Hasil menunjukkan peningkatan efisiensi yang signifikan. Dari partisi-partisi kecil tersebut, saya dapat mengekstrak dan memproses 312.074 bangunan yang secara akurat mewakili area Jakarta Pusat. Data ini, meskipun hanya sebagian kecil dari dataset global, sudah cukup untuk analisis mendalam tanpa membebani sistem dengan data yang tidak relevan. Dengan demikian, Quadtree partitioning terbukti menjadi strategi penting untuk mengoptimalkan pengolahan data geospasial skala besar, menghasilkan pemrosesan yang lebih cepat, efisien, dan hemat sumber daya.
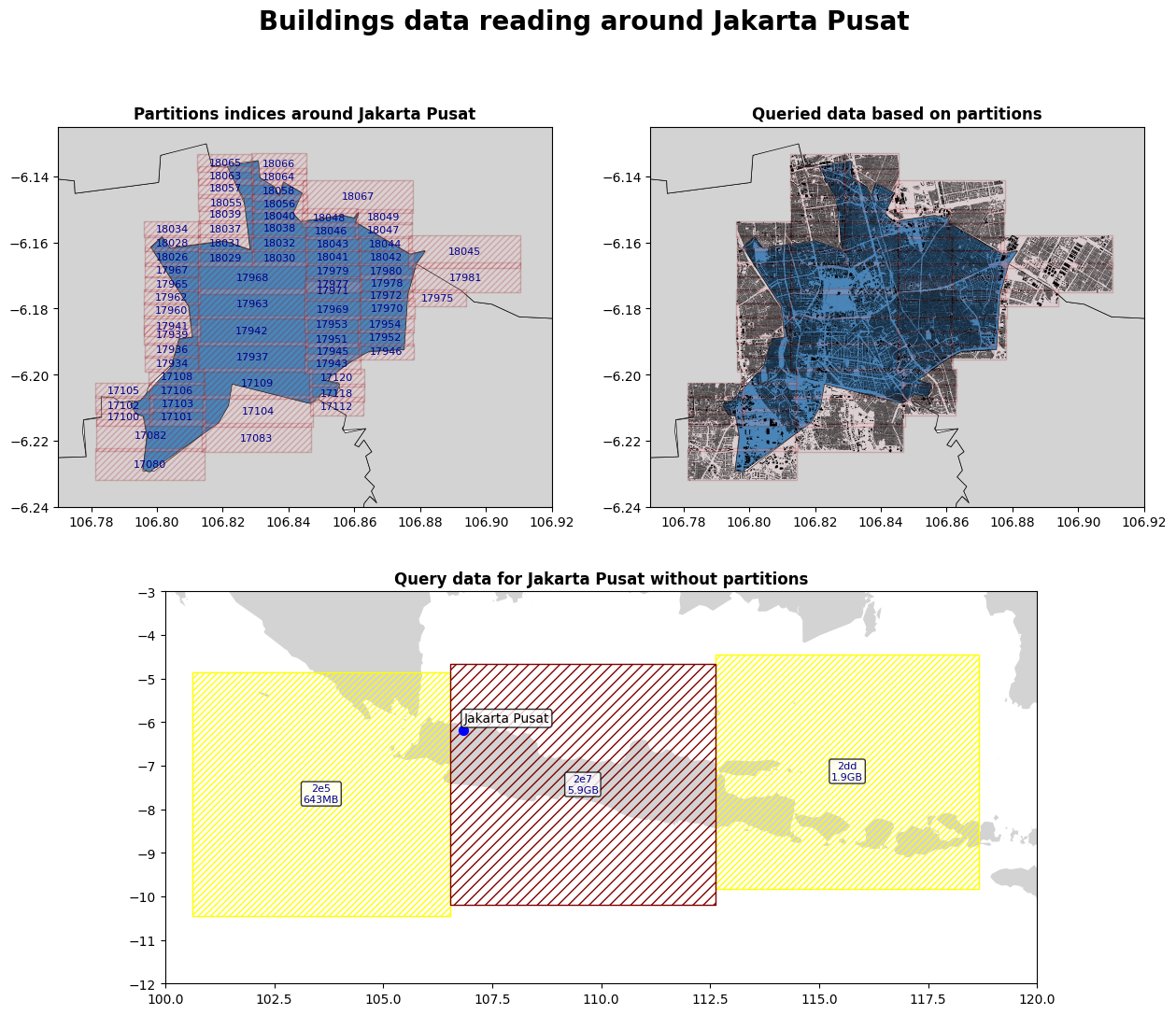
Gambar 8. Perbandingan pemanggilan data bangunan dengan dan tidak menggunakan partisi Quadtree di area Jakarta Pusat
Rekomendasi
Dalam mengoptimalkan pengolahan data geospasial, pemilihan metode partisi Quadtree perlu disesuaikan dengan pola distribusi spasial data. Berdasarkan karakteristik data, berikut dua pendekatan utama untuk memaksimalkan efisiensi.
1. Partisi Berdasarkan Nilai Maksimum Derajat Bujur-Lintang
Metode ini sangat cocok untuk data dengan distribusi spasial merata, seperti data raster (citra satelit, peta elevasi, atau data suhu). Karena setiap kuadran memiliki kepadatan data yang relatif seragam, partisi Quadtree dapat dibuat berdasarkan batas maksimum derajat bujur dan lintang yang telah ditentukan. Pembagian ini menghasilkan partisi yang seimbang, memastikan setiap bagian memiliki volume data yang hampir sama, sehingga mengoptimalkan proses komputasi yang homogen di seluruh area dan mencegah ketidakseimbangan kepadatan antar kuadran.
2. Partisi Berdasarkan Nilai Maksimum Fitur
Metode ini lebih tepat untuk data dengan distribusi tidak merata, seperti data vektor lokasi objek fisik (bangunan, pohon, atau titik populasi). Pada dataset seperti Google Open Building, area perkotaan memiliki kepadatan bangunan jauh lebih tinggi dibanding kawasan perdesaan. Dengan menetapkan batas maksimum fitur (misalnya 10.000 bangunan per partisi), Quadtree akan menyesuaikan pembagiannya secara dinamis. Di area padat, kuadran akan dibagi menjadi bagian-bagian yang lebih kecil dan detail, sementara di area pedesaan, kuadran tetap besar karena jumlah fitur yang sedikit. Pendekatan ini efektif karena menghindari partisi yang tidak perlu pada area kosong dan memastikan beban pemrosesan yang optimal di setiap partisi.
3. Penyesuaian dengan Statistik Data
Apapun metode yang dipilih, penggunaan partisi harus disesuaikan dengan statistik data untuk menghindari over-partitioning (partisi berlebihan) atau under-partitioning (partisi kurang). Over-partitioning terjadi ketika data dibagi menjadi terlalu banyak partisi kecil yang masing-masing hanya berisi sedikit fitur. Hal ini meningkatkan overhead dan memperlambat proses pembacaan data karena sistem harus membuka dan menutup terlalu banyak file. Sebaliknya, under-partitioning menghasilkan sedikit partisi berukuran besar yang membebani memori dan memperlambat pemrosesan, mirip dengan situasi tanpa partisi. Oleh karena itu, analisis statistik data seperti kepadatan fitur rata-rata menjadi langkah krusial untuk menentukan parameter partisi optimal, mencapai keseimbangan antara jumlah partisi yang wajar dan ukuran data yang efisien.
Kesimpulan
Dalam pembahasan ini, saya telah menjelaskan bagaimana Quadtree partitioning menjadi solusi efektif untuk mengelola dan memproses data geospasial besar dengan distribusi tidak merata, seperti data Google Open Building. Analisis kasus Jakarta Pusat membuktikan bagaimana metode ini mengurangi beban data dari gigabyte menjadi megabyte, secara signifikan meningkatkan efisiensi komputasi.
Selain itu, saya juga menerapkan metode serupa untuk dataset dengan distribusi yang lebih merata, yaitu data tutupan pohon. Berbeda dengan bangunan yang terkonsentrasi di area urban, tutupan pohon memiliki pola distribusi yang relatif seragam di seluruh wilayah. Dalam kasus ini, pendekatan partisi berdasarkan nilai maksimum derajat bujur-lintang terbukti lebih optimal, menghasilkan kuadran dengan ukuran yang konsisten. Hal ini menunjukkan fleksibilitas metode Quadtree yang dapat disesuaikan dengan karakteristik distribusi spasial dari berbagai jenis dataset.
Namun, Quadtree hanyalah satu dari beberapa model partisi spasial yang tersedia. Meskipun efektif untuk area lokal, keterbatasan Quadtree terletak pada penggunaan proyeksi planar —simulasi bahwa bumi adalah permukaan datar— yang mendistorsi data ketika diterapkan secara global. Untuk dataset berskala dunia, dunia geospasial menawarkan metode lain yang lebih handal dengan keunggulan unik, seperti S2Sphere yang menggunakan geometri bola dan H3Hexagon yang menggunakan sistem grid heksagonal global untuk mempertahankan hubungan spasial yang konsisten di seluruh planet.
Jika Anda ingin memahami cara kerja model-model ini dan perbandingannya dengan Quadtree, ikuti tulisan saya berikutnya. Kita akan mengeksplorasi efektivitas S2Sphere yang berbasis bola dunia (spherical) dan H3Hexagon dengan sistem grid heksagonalnya—bagaimana keduanya dapat menjadi solusi alternatif yang inovatif.
Penasaran mana yang paling sesuai untuk proyek Anda? Nantikan ulasan lengkapnya!
Versi artikel asli dalam Bahasa Inggris sebagai berikut.

![[GEODATA] Tutupan Lahan Indonesia](https://mapidstorage.s3.amazonaws.com/general_image/mapidseeit/1684312961161_COVER%20GEODATA_%20Tutupan%20Lahan.png)
![[GEODATA] Status Ekonomi dan Sosial (SES) Indonesia](https://mapidstorage.s3.amazonaws.com/general_image/mapidseeit/1693454652933_20230831-085941.jpg.jpeg)
![[GEODATA] Point of Interest (POI)](https://mapidstorage.s3-ap-southeast-1.amazonaws.com/foto_doc/mapidseeit/doc_1648452337_d8074cde-5aef-4820-88ba-b6cc500a7e04.jpeg)